
Computational Fluid Dynamics (CFD) has long been central to modern engineering design. From aircraft wings to offshore structures, the ability to numerically solve the governing equations of fluid flow underpins many advances in aerospace, automotive, energy, and environmental fields.

Yet, solving the Navier–Stokes equations for real-world, turbulent, multi-scale flows can be computationally prohibitive. Classical turbulence models, like Reynolds-Averaged Navier–Stokes (RANS), often rely on empirical closures that limit accuracy for complex phenomena such as separation, swirl, or transition.
Recent progress in data availability, high-fidelity simulations, and machine learning has opened new pathways for data-driven fluid mechanics — using large datasets and modern algorithms to enhance or accelerate CFD without abandoning the fundamental physics.
The Classical Foundation
At the heart of CFD are the incompressible Navier–Stokes equations:


where:
is the velocity field,
is pressure,
is fluid density,
is kinematic viscosity,
represents external body forces.
For turbulent flows, these equations are often time-averaged to produce the RANS equations:

The Reynolds stress tensor, 


Why Data-Driven Methods?
With the growth of high-fidelity DNS and LES data and advanced sensors, engineers now have access to vast datasets capturing complex flow physics. Machine learning makes it possible to learn patterns within these datasets and construct more accurate closures or surrogate models.
Rather than replacing physics-based equations, these methods embed or supplement them with data-driven components.
Data-Driven Turbulence Closures
A major focus is improving the modelling of the Reynolds stress tensor. The anisotropic component is often targeted:

where the turbulent kinetic energy is:

In data-driven approaches, a neural network 

Careful feature selection ensures the model respects fundamental invariances such as Galilean invariance and rotational symmetry.
Surrogate Modelling
In design workflows, thousands of CFD runs may be required for optimisation or uncertainty quantification. Full high-fidelity CFD makes this impractical. A surrogate model approximates the mapping between input parameters and quantities of interest:

where 
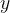
Once trained, these models provide near-instant predictions, supporting rapid design iteration.
Reduced Order Modelling (ROM)
A related strategy compresses large flow fields into a small set of dominant modes. Proper Orthogonal Decomposition (POD) is a widely used method:

Here, 

Physics-Informed Neural Networks (PINNs)
Purely data-driven models can easily violate conservation laws if they do not explicitly enforce the governing equations. PINNs address this by embedding the fundamental physical laws of fluid mechanics directly into the machine learning process.
For incompressible flow, the network’s predicted output must satisfy two key conditions: conservation of mass (continuity) and conservation of momentum. In practice, this means that the model must account for how local acceleration, convective transport, pressure gradients, viscous diffusion, and external body forces all interact.
By penalising any deviation from these physical constraints during training, PINNs ensure that the learned model remains faithful to the underlying fluid dynamics. This helps maintain physical realism and reliability, even when using machine-learned components to handle complex or hard-to-model aspects of the flow.
Practical Applications
Aerospace: Surrogate models reduce turnaround time for drag and lift predictions, enabling more efficient wing and fuselage designs.
Automotive: Data-driven flow predictions support digital twins for real-time aerodynamic adjustments or thermal management.
Energy: Wind farm layouts benefit from fast surrogate models that predict wake interactions between turbines.

Biomedical: Hybrid models estimate patient-specific blood flow fields from sparse imaging, improving medical device design.
Environmental: Faster, data-driven dispersion models improve air quality predictions in urban planning and emergency scenarios.

Challenges and Outlook
While promising, data-driven CFD must address several practical concerns:
- Maintaining physical consistency in predictions.
- Ensuring generalisation to new geometries and conditions beyond the training data.
- Building trust among engineers who need to know where the model’s limits lie.
The future is likely to be hybrid: rigorous physics solvers remain the foundation, while data-driven components enhance speed and insight where traditional methods struggle.
Summary
Data-driven fluid mechanics is not about discarding the Navier–Stokes equations but about augmenting them with the full potential of modern data and machine learning. This integration enables more accurate, faster, and more flexible predictions for the increasingly complex flow problems that engineers face today.